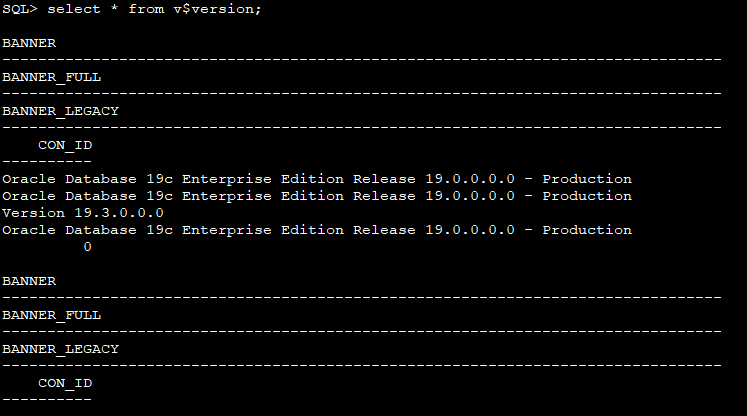
select /*+ result_cache */ count(*) from test_objs a, test_segs b where a.object_name <> b.segment_name;
- 쿼리 결과를 caching 하라는 힌트이다.
- 조회 용도의 select 되는 건이 많지 않고, 값이 변하지 않는 데이터(예를 들면 과거 매출 데이터) 등을 집계 / 분석하는 쿼리에 result_cache 힌트를 사용하면 유용하다.
- caching 할 크기가 너무 커서 result_cache_max_size, result_cache_max_result 파라미터 값을 넘어가면 캐싱 기능을 사용할 수 없다.
- Data dictionary, Temporary Table에 대한 쿼리 또는 시퀀스에 대한 curval, nextval에 대한 쿼리는 캐시되지 않는다.
관련 파라미터
SQL> show parameter result_cache
NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ client_result_cache_lag big integer 3000 client_result_cache_size big integer 0 result_cache_max_result integer 5 result_cache_max_size big integer 11904K result_cache_mode string MANUAL result_cache_remote_expiration integer 0
result_cache_max_result : 단일 result_set 캐시안에 캐시될 최대 비율(%)이며, 이를 초과할 경우 캐싱 기능을 사용할 수 없는 invalid 상태가 된다.
result_cache_mode : default 값이 manual이며, result_cache 힌트를 명시해야 결과값 캐싱이 된다.
result_cache_max_size : 캐싱되는 최대 바이트 사이즈 이다.
result_cache_remote_expiration : 원격오브젝트에 대한 쿼리 결과로 캐싱되어 유효한 시간
2. result_cache 힌트를 사용한 SQL 수행 결과
SQL> select /*+ result_cache */ count(*) from test_objs a, test_segs b where a.object_name <> b.segment_name; 2 3
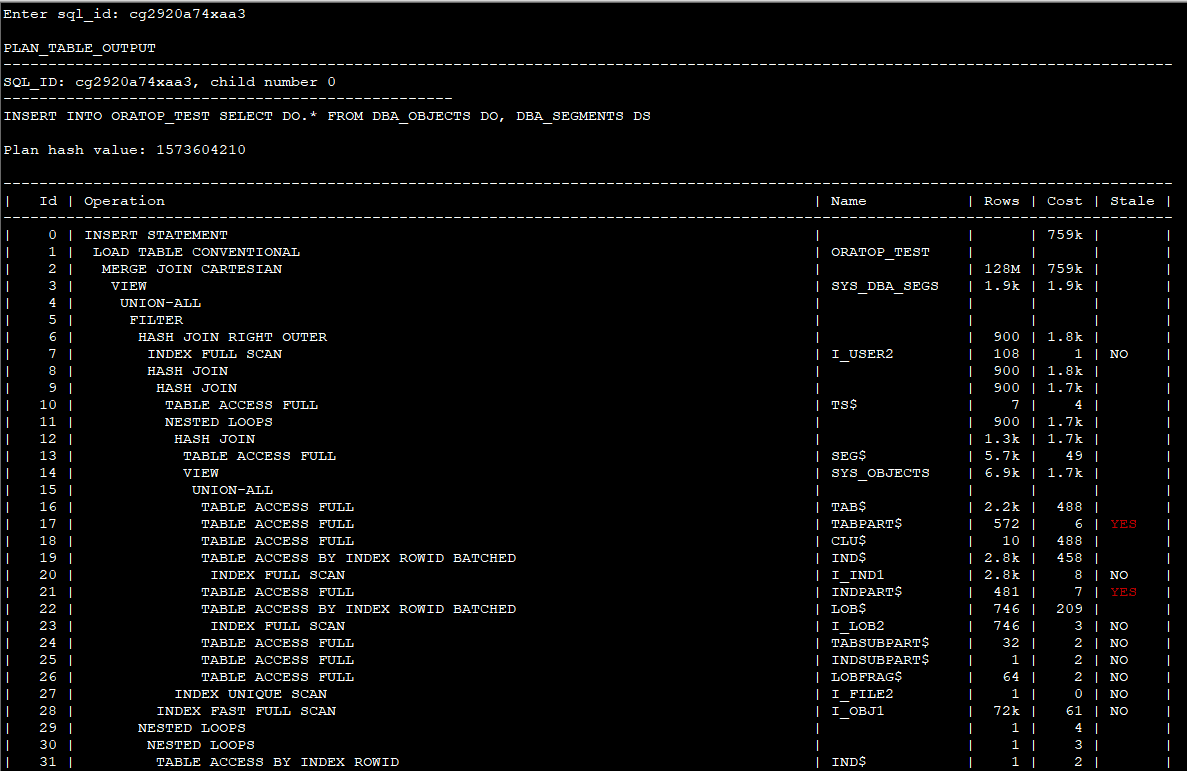
3. 수행한 SQL의 sql_id를 확인한다. jgh_01을 comment로 넣었으므로 이 값으로 like 검색하면 확인할 수 있다.
조회한 sql_id는 985k8bddta87t 임을 확인할 수 있다.
4. 3에서 확인한 sql_id로 dbms_xplan.display_cursor로 SQL의 통계를 확인할 수 있다.
set lines 200
set pages 10000
위 옵션은 SQL*PLUS에서 한줄의 표현할 수 있는 라인의 갯수와 페이지의 크기를 지정할 수 있다.
dbms_xplan.display_cursor 수행시 아래와 같은 결과를 얻을 수 있다.
각 항목의 설명은 캡쳐된 화면 아래에서 확인할 수 있다.
Id, Operation, Name
이 부분은 SQL plan의 정보이다. 객체에 대한 Access 순서(driving)와 Access 방법(index scan, table scan, join의 순서)을 나타낸다. 참고로 Access 순서를 변경할 수 있는 힌트절은 ordered, leading 등이 있고 Access 방법을 변경할 수 있는 힌트절은 use_nl, use_hash, use_merge, index, full 등이 있다.
Starts
오퍼레이션을 수행한 횟수를 의미한다. Starts * E-Rows의 값이 A-Rows 값과 비슷하다면 통계정보의 예측 Row 수와 실제 실행 결과에 따른 실제 Row 수가 유사함을 알 수 있다. 만약 값에 큰 차이가 있다면 통계정보가 실제의 정보를 제대로 반영하지 못했다고 생각할 수 있다. 이로인해 오라클 DBMS의 옵티마이져가 잘못된 실행 계획을 수립할 수도 있으므로 이 때는 SQL의 튜닝이 필요하다.
E-Rows (Estimated Rows)
통계정보에 근거한 예측 Row 수를 의미한다. 통계정보를 갱신할수록 값이 매번 다를 수 있으며, 대부분의 DB 운영에서는 통계정보를 수시로 갱신하지 않으므로 해당 값에 큰 의미를 둘 필요는 없다. 하지만 E-Rows 값과 A-Rows 값이 현격하게 차이가 있다면 오라클이 잘못된 실행계획을 세울 수도 있음을 인지해야 하며 통계정보 생성을 검토해 보아야 한다.
A-Rows (Actual Rows)
쿼리 실행 결과에 따른 실제 수행 시간을 의미한다. 하지만 실행 시점의 여러 상황에 늘 가변적이고 또한 메모리에 올라온 Block의 수에 따라서 수행 시간이 달라지므로 해당 값에 큰 의미를 둘 필요는 없다.
Buffer (Logical Reads)
논리적인 Block의 수를 의미한다. 해당 값은 오라클 옵티마이저가 일한 총량을 의미하므로, 튜닝을 진행할 때 대부분의 튜너들이 가장 중요하게 생각하는 요소 중 하나이다.
Reads (Physical Reads)
물리적인 Get Block 수를 의미한다. 동일한 쿼리일 경우에는 값이 0인 것을 보면 알 수 있듯이 메모리에서 읽어 온 Block은 제외된다. 해당 값에 큰 의미를 둘 필요는 없다.
위의 항목들 중 튜닝 시에 가장 중요하게 생각되고 활용되는 값은 Buffers와 A-Rows이다. Buffers 값을 통해서 Get Block의 총량을 알 수 있고, A-Rows를 통해 실행 계획 단계별로 실제 Row 수를 알 수 있기 때문이다.
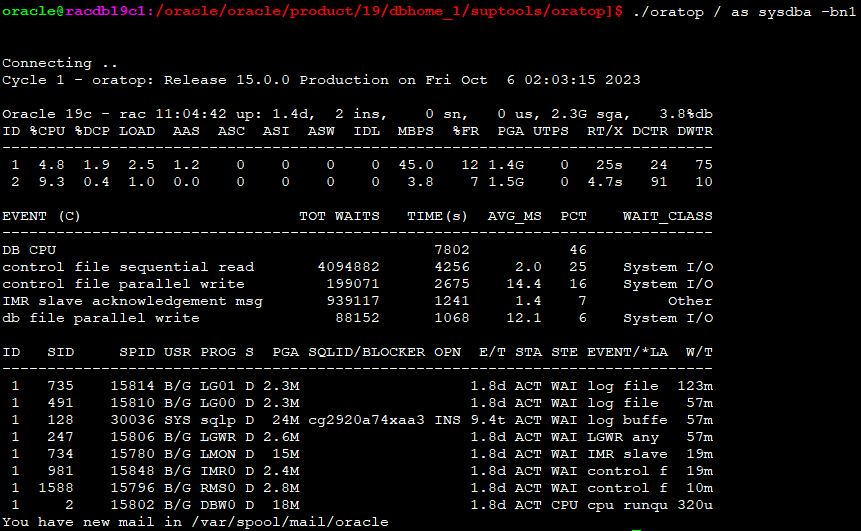
오라클이 제공하는 Oracle Call Interface(OCI) API를 이용한, 텍스트 기반 데이터베이스 모니터링 툴입니다. 현재 데이터베이스 활동 상태와 성능을 모니터링하고, 경합과 병목지점을 식별할 수 있습니다. 오라클 데이터베이스 11gR2 버전부터 지원하며, 유닉스 top 유틸리티와 유사한 인터페이스를 가지고 있습니다.
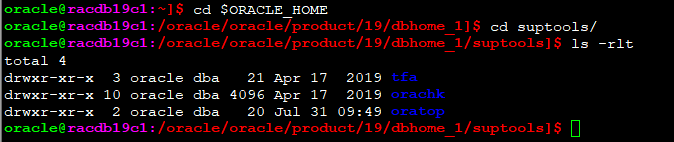
바이너리 파일 위치
oracle$ cd $ORACLE_HOME/suptools
oracle$ ls oratop tfa
주요 특징
- 프로세스, SQL 모니터링 - 실시간 Wait Event - Active Data Guard 지원 - 멀티태넌트 CDB 지원
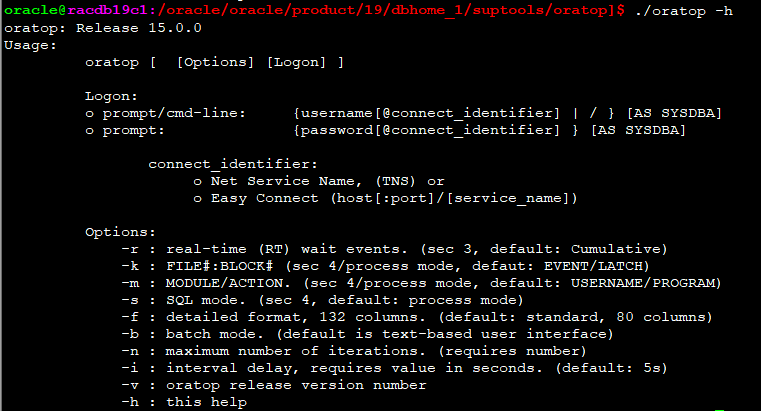
수행방법
./oratop -h
=> 수행방법 및 도움말.
local 데이터베이스를 모니터링 할 경우
$ ./oratop -i 10 / as sysdba
remote 데이터베이스를 모니터링 할 경우
$ ./oratop -i 10 username/password@tns_alias
$ ./oratop -i 10 system/manager@tns_alias
예) ./oratop -i 10 -f -m / as sysdba
10초 간격으로 Module/Action 정보를 포함해서 상세 포맷으로 데이터베이스 정보를 출력하도록 oratop을 실행해보겠습니다. 참고로, 데이터베이스 statistics_level 레벨이 "BASIC"으로 설정되어 있으면, oratop이 모니터링 정보를 제대로 가져올 수 없다.
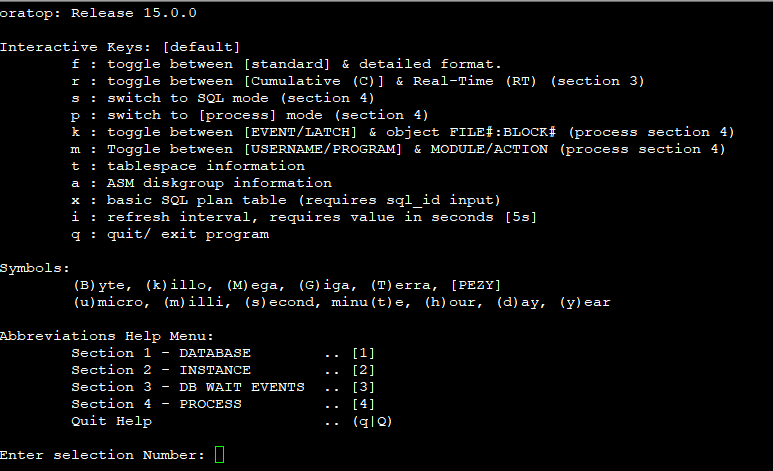
기본 모드로 보인다.(standard format)
f 입력시 자세한 모드로 볼 수 있다.(detailed format)
각 항목의 의미
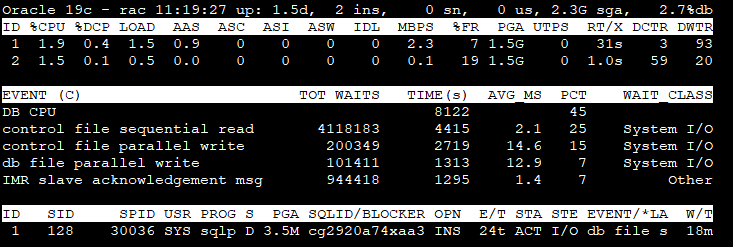
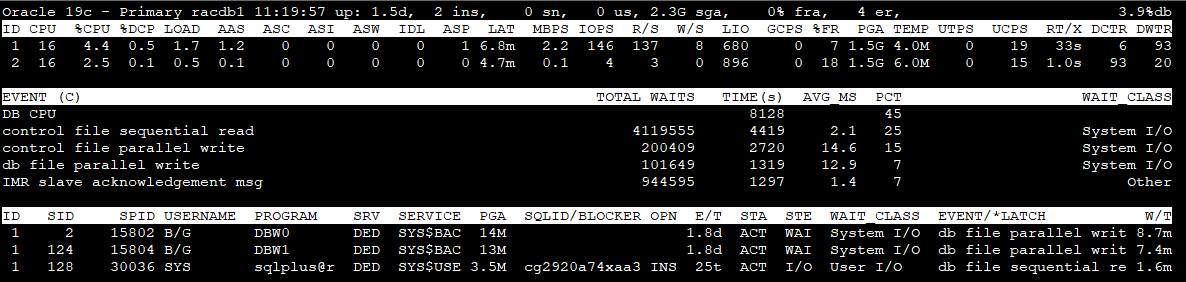
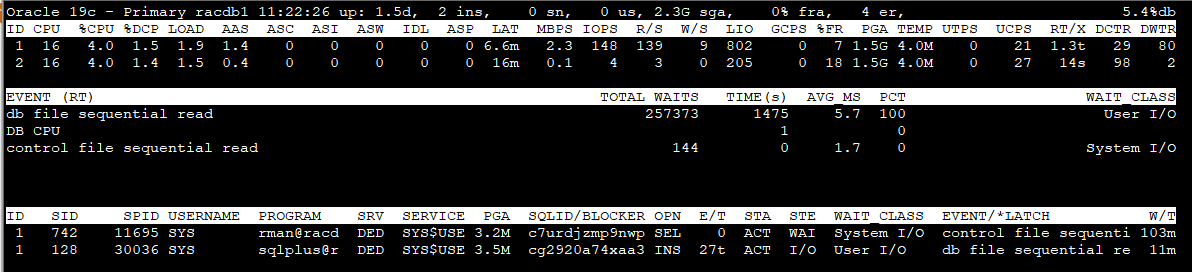
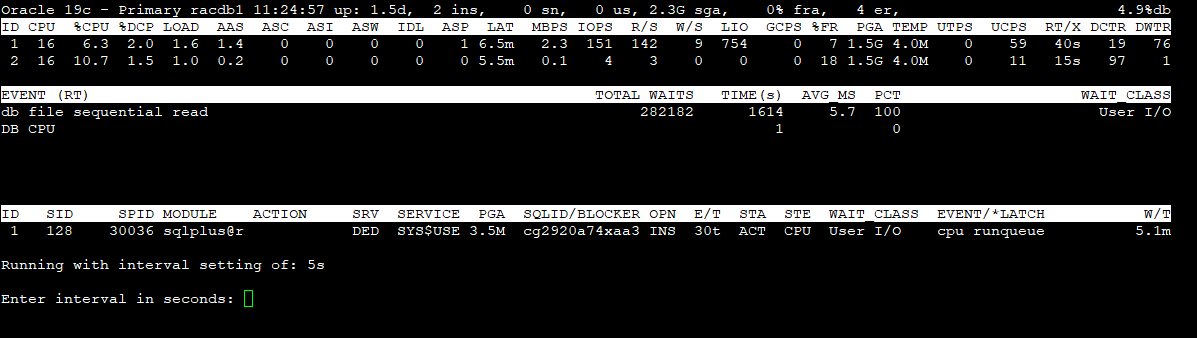
Section 1 - Global Database information
Version : Oracle major version role : database role db name : db_unique_name time : time as of the most recent stats (hh24:mi:ss) up : database uptime (UTC) ins : total number of instance(s) sn : total user sessions (non-predefined) us : number of distinct users (non-predefined) sga : system global area (SGA) fra : flashback recovery area %used er : diag active problem count (checked once at start) %db : %Active Database (work)
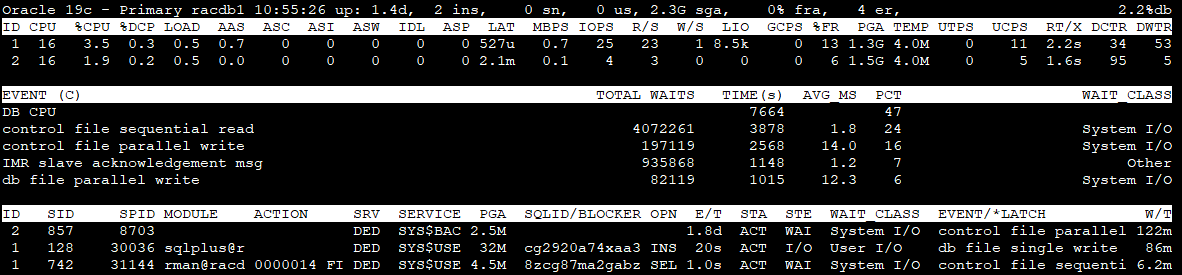
Section 2 - Top 5 Instance(s) Activity ordered by Database Wait Time Ratio Desc
ID : Instance Id. CPU : CPU Count %CPU : Host CPU Utilization (%busy) %DCP : Database cpu usage as %CPU LOAD : Current OS Load AAS : Average Active Sessions (dbtime (s/s)) ASC : Active Sessions on CPU ASI : Active Sessions waiting on User I/O ASW : Active Sessions Waiting on other events IDL : Idle User Sessions (non-predefined) ASP : Active Parallel Sessions (F/G) LAT : Average Synchronous Single-Block Read Latency (Threshold: 20ms) MBPS : I/O Megabytes per Second (throughput R/W) IOPS : I/O Requests per second (R/W) R/S : Physical Read Total IO Requests Per Sec W/S : Physical Write Total IO Requests Per Sec LIO : Logical Reads Per Sec GCPS : GC (CR+Current) Block Received Per Second %FR : Shared Pool Free % PGA : Total PGA Allocated TEMP : Temp Space Used UTPS : User Transaction Per Sec UCPS : User Calls Per Sec RT/X : Response Time Per Txn DCTR : Database CPU Time Ratio DWTR : Database Wait Time Ratio
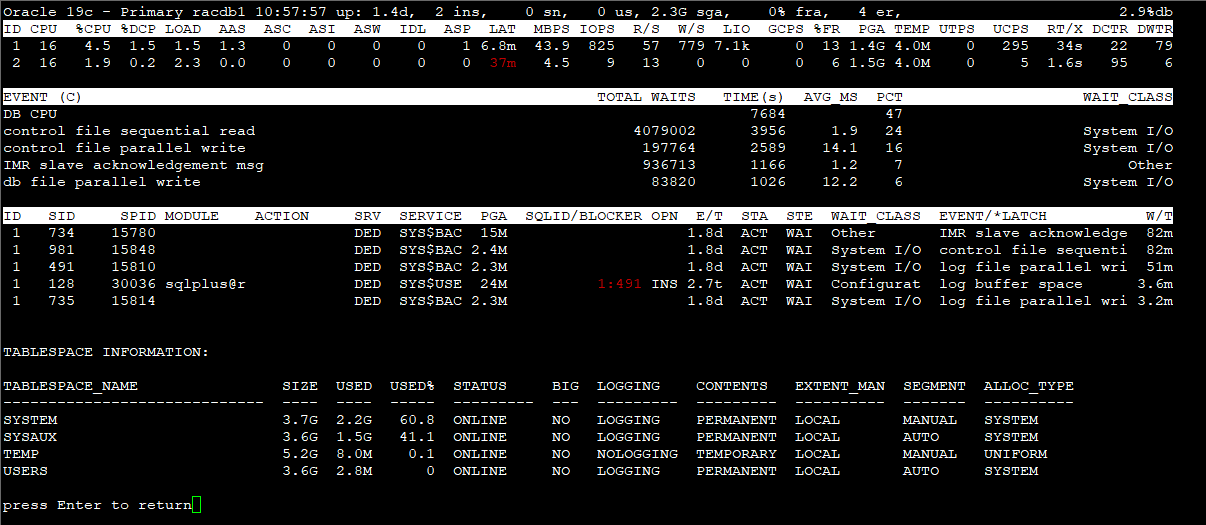
Section 3 - Top 5 Timed Events ordered by wait time desc (Cluster-wide, non-idle)
EVENT : wait event name (RT) : Real-Time mode TOTAL WAITS : total waits TIME(s) : total wait time in seconds) AVG_MS : average wait time in milliseconds PCT : percent of wait time (all events) WAIT_CLASS : name of the wait class
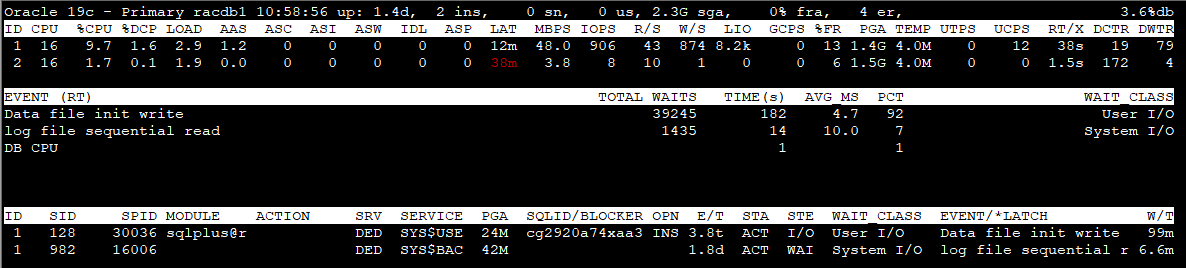
Section 4 - Non-Idle processes ordered by event wait time desc.
ID : inst_id SID : session identifier SPID : oraserver process os id MODULE : Name of the currently executing module ACTION : Name of the currently executing action SRV : SERVER (dedicated, shared, etc.) SERVICE : db service_name PGA : pga_used_mem SQL_ID/BLOCKER : sql_id or the final blocker's (inst:sid) OPN : operation name, e.g. select E/T : session elapsed time (active/inactive) STA : ACTive|INActive|KILled|CAChed|SNIped STE : process state, e.g. on CPU or user I/O or WAIting WAIT_CLASS : wait_class for the named event EVENT/*LATCH : session wait event name. Auto toggle with *latch name W/T : event wait time (Threshold: 1s)
SELECT 거래일자 , sum(decode(지수구분코드, '1', 지수종가, 0) kospi200_idx, , sum(decode(지수구분코드, '1', 누적거래량, 0) kospi200_idx_trdvol , sum(decode(지수구분코드, '2', 지수종가, 0) kosdaq_idx , sum(decode(지수구분코드, '2', 누적거래량, 0) kosdaq_idx_trdvol FROM 일별지수업종별거래및시세 a WHERE 거래일자 between :startDd and :endDd AND 지수구분코드 || 지수업종코드 in ('1001','2003') GROUP BY 거래일자;
튜닝 포인트
지수구분코드 + 지수업종코드 + 거래일자 컬럼에 해당되는 인덱스가 있으나
지수구분코드||지수업종코드 이렇게 인덱스에 포함된 컬럼이 가공되어 있어
INDEX RANGE SCAN이 되지 못하고 있다.
INDEX RANGE SCAN이 될 수 있도록 인덱스에 포함된 컬럼을 가공하지 않도록 아래와 같이 조건을 변경한다.
변경 전
AND 지수구분코드 || 지수업종코드 in ('1001','2003')
변경 후
AND (지수구분코드, 지수업종코드) in (('1','001'),('2','003'))
튜닝 후 전체 쿼리
SELECT 거래일자 , sum(decode(지수구분코드, '1', 지수종가, 0) kospi200_idx, , sum(decode(지수구분코드, '1', 누적거래량, 0) kospi200_idx_trdvol , sum(decode(지수구분코드, '2', 지수종가, 0) kosdaq_idx , sum(decode(지수구분코드, '2', 누적거래량, 0) kosdaq_idx_trdvol FROM 일별지수업종별거래및시세 a WHERE 거래일자 between :startDd and :endDd AND (지수구분코드, 지수업종코드) in (('1','001'),('2','003')) GROUP BY 거래일자;
직업은 오라클 DBA,
관심분야는 오라클DBMS, 경제, 프리젠테이션, 여행 입니다.
다양한 경험을 하고 지식을 쌓고, 지혜를 얻기를 좋아합니다.
그리고 그 경험, 지식, 지혜를 많은 사람들과 나누는 것이 제가 살아가는 이유이고, 행복입니다.
혹시나 같이 오라클, 경제, 프리젠테이션, 여행 등 제 관심분야에 대해
같이 공유하고 싶은 분들은 쪽지나 방명록을 남겨주시면
온/오프라인에서 무엇이든 같이 만들어갈 수 있을 것 같습니다.